
ファイルサーバーの中のファイルを素早く探し出します。
企業内のサイロ化されてしまった情報資産への効率的な情報取得を、無制限ライセンスで安価に行えるエンタープライズサーチソリューションです。データ検索にかかる人的コストを大幅にカットすることができます。
おすすめのお客様
- ファイルサーバー内のファイルの検索に時間がかかる。
- ファイルがどこに行ったか分からなくなった。
特長
-
桁違いの検索結果の速さ
ローラー処理により全文検索のインデックス作成を行っているため、高速な検索結果を得られます。試用環境におけるファイルサーバー内の22万ファイルのインデックス作成時間は作成に20分、更新に5分という高速な結果が得られています。
-
分かりやすいインターフェース
Googleライクのわかりやすいインターフェースで、検索結果を可視化します。検索結果にはファイル名、ファイル種別、本文の抜粋、保存場所など必要な情報が的確に表示されます。
-
安心の無制限ライセンス
ユーザー数や文書数、サーバーのCPU数によって金額変動する事無く「無制限ライセンス」として安心してご利用いただけます。検索対象が多いほどコストメリットが大きくなります。
検索時の動作
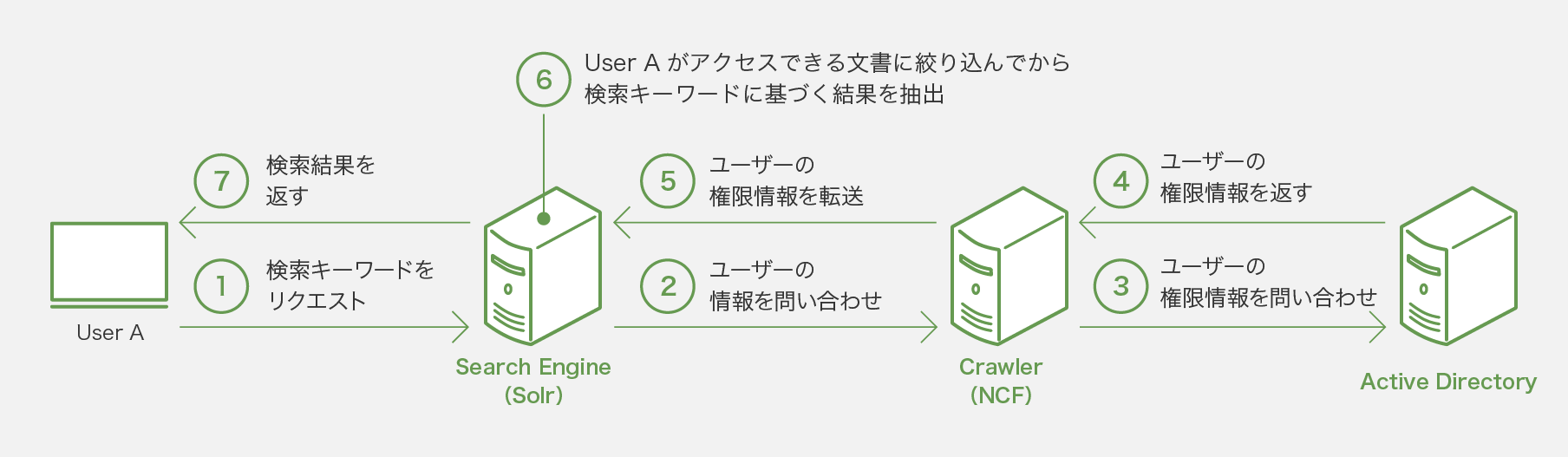
Crawler(NCF)
検索対象となる社内の共有サーバー等から文書を収集、及びActive Directoryなどの権限管理サーバーからユーザー権限情報を取得します。
Search Engine(Solr)
Crawler(NCF)が収集した文書を解析し、インデックス化します。
Crawler(NCF)、Search Engine(Solr)
同一サーバーでも別々のサーバーでも動作させることが可能です。
検索結果画面
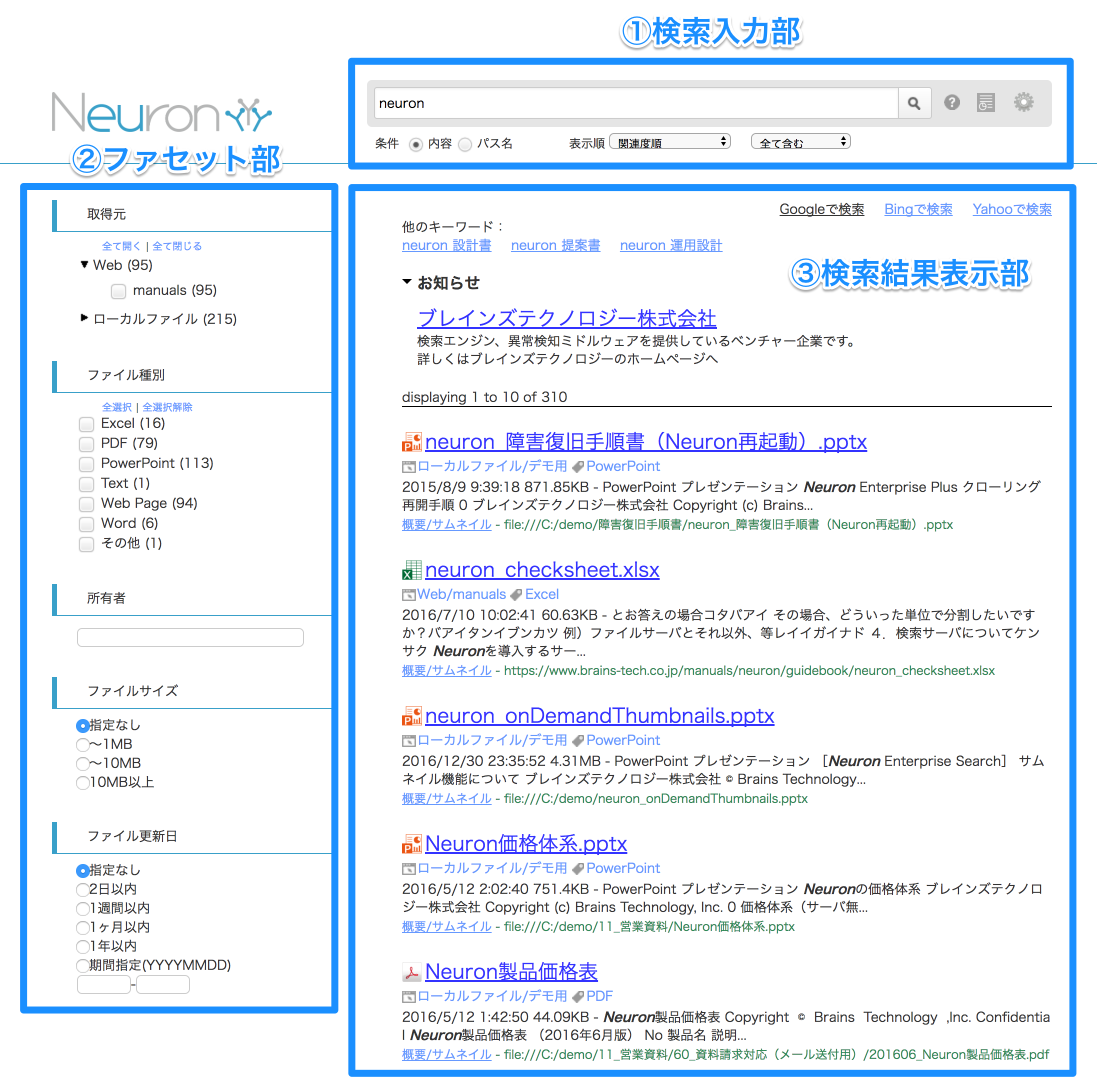
1.検索入力部
ここでは、検索窓に検索したいキーワードを入力します。このキーワードは文章・単語どちらでもかまいません。
条件として以下のチェックボックスから選択できます。
-
内容
ファイル名を含む全文が検索対象となります。
-
パス名
ファイル名及びファイルのパス名のみ検索対象となります。
表示順リストにて、結果の並び順を変えることができます。(関連度順、新しい順、古い順、人気順、ファイル名(昇順)、ファイル名(降順))
2.ファセット部
ここでは以下の5種類で検索結果を絞り込むことができます。
| 絞り込みの種類 | 説明 |
| 取得元 | お客さまがクロールジョブを設定した際に、付与するカテゴリ情報がそのまま取得元情報になります。標準で2階層の設定ができます。例えば、ある部署のレポジトリをクロールする際に、部署の情報をカテゴリに付与することで、その部署に関係するコンテンツのみ検索対象とすることが可能になります。 |
|---|---|
| ファイル種別 | Neuronが、インデックス生成時に読み込んだ文書のMIMEタイプ情報から自動的にファイル種別を判別し、判別された種類がファセット項目に並びます。 |
| 所有者 | ファイルのメタ情報である所有者で絞り込みができます。所有者名が、かな・カタカナ・漢字の場合は部分一致・英数字の場合は完全一致での絞り込みになります。 |
| ファイルサイズ | 指定なし、1MBまで、10MBまで、それ以上の4つのサイズによる絞り込みができます。もっと細かくすることも可能です。本番導入時にカスタマイズ提供可能です。 |
| ファイル更新日 | ファイルの最終更新日付を基に絞り込みます。こちらもファイルサイズ同様本番導入時にカスタマイズ提供可能です。 |
結果表示部の文書情報
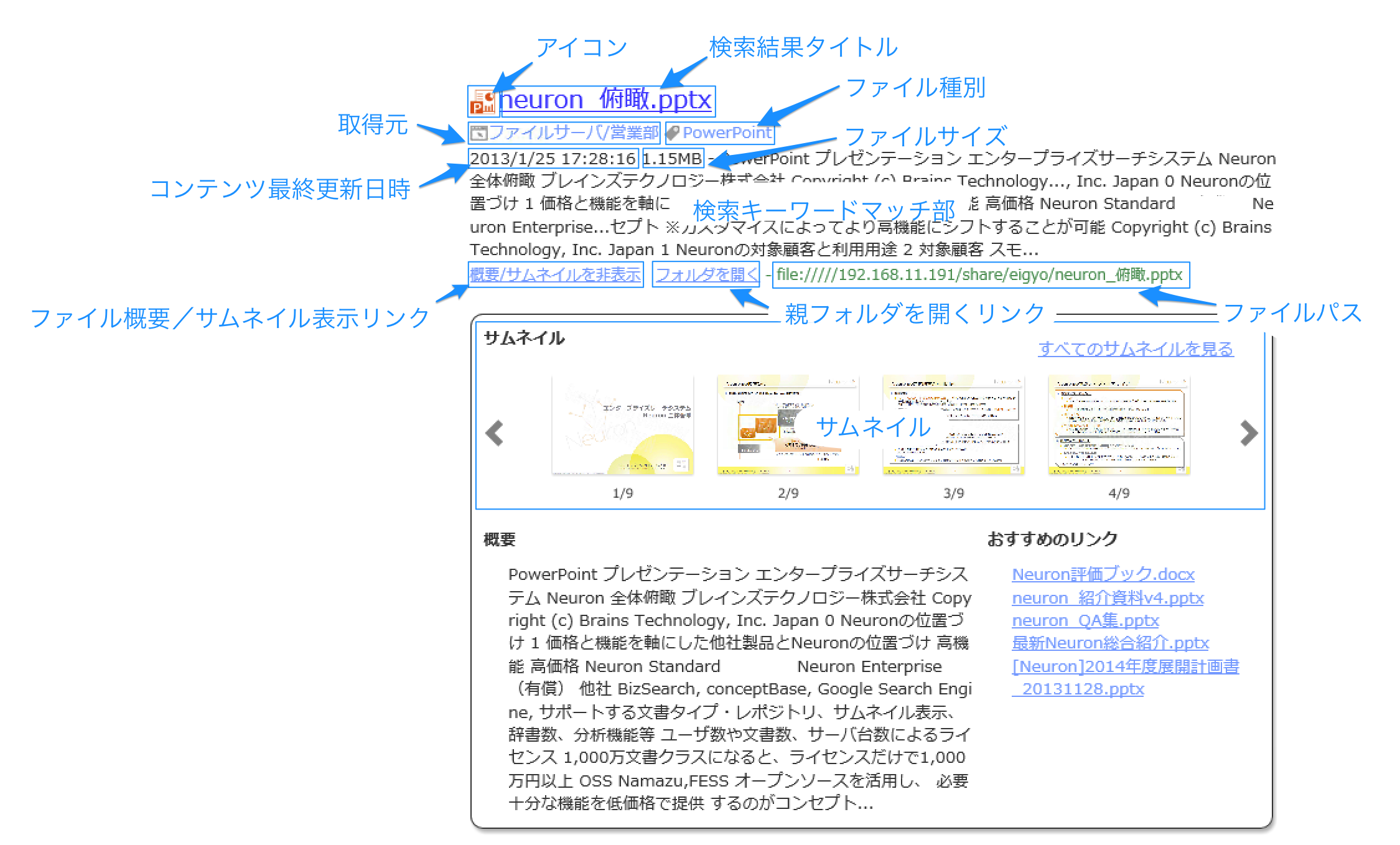
| 情報 | 説明 |
| アイコン | 文書の種類に応じたアイコンが表示されます。 |
|---|---|
| 検索結果タイトル | HTMLの場合はタイトル、それ以外の場合はファイル名が表示されます。 |
| 取得元 | クロールジョブで設定した取得元名が表示されます。 |
| ファイル種別 | Neuronで自動判別したMIMEタイプが表示されます。 |
| コンテンツ最終更新日時 | ファイルの最終更新日時が現地時間に合わせて表示されます。 |
| ファイルサイズ | ファイルのサイズが表示されます。 |
| 検索キーワードマッチ部 | キーワードがヒットした前後の文が表示され、ヒットした部分(ハイライト)は太字・斜体文字で表示されます。なお、この設定は変更することができます。 |
| ファイル概要/サムネイル表示リンク | クリックすると概要、およびサムネイル(オプション導入時)が表示されます(下記参照)。 |
| 親フォルダを開くリンク | ファイルが保存されているフォルダを開きます(Internet Explorer のみ表示されます)。 |
| ファイルパス | ファイルの実際の場所情報が表示されます。 |



